
لم يكن Google I/O 2025 أبدًا عن الدقة. هذا العام ، تخلى الشركة عن زيادة التزايد ، حيث قدمت سلسلة من ترقيات الذكاء الاصطناعى التوليدي التي تهدف إلى إعادة رسم الخريطة للبحث والفيديو والإبداع الرقمي.
The Linchpin: Gemini ، عائلة النموذج القادم من Google ، تعمل الآن على تشغيل كل شيء من نتائج البحث إلى تخليق الفيديو وإنشاء صور عالية الدقة-مما يخرج من أراضي جديدة في سباق محدد بشكل متزايد من خلال السرعة ، ومدى الصيفية ، التي يمكن أن تولدها منظمة العفو الدولية.
The ShowStopper هو Veo 3 ، أول مولد فيديو لـ Google AI الذي لا ينشئ الصور المرئية فحسب ، بل يتوافق مع الضوضاء الصوتية – الضوضاء ، والتأثيرات ، وحتى الحوار – مع اللقطات مباشرة. تدخل مطالبات النص والصورة ، ويخرج فيديو 4K المنتج بالكامل.
يمثل هذا أول طراز فيديو واسع النطاق قادر على توليد الصوت والمرئيات في وقت واحد-وهو اتجاه بدأ مع العرض Alpha ، وهو نموذج غير منشور ، لكن VEO3 يوفر المزيد من التنوع بكثير ، مما يولد أنماطًا مختلفة تتجاوز الرسوم المتحركة الكرتونية البسيطة ثنائية الأبعاد.
وقال نائب الرئيس لشركة Google Labs Josh Woodward أثناء الإطلاق: “نحن ندخل حقبة جديدة من الإنشاء مع توليد الصوت والفيديو مجتمعة”. إنه تحد مباشر لقادة توليد الفيديو الحاليين-Kkling و Hunyuan و Luma و Wan و Openai's Sora-يوضحون VEO كحل الكل في واحد بدلاً من طلب أدوات متعددة.
إلى جانب VEO3 ، يتخطى Imagen 4 – أحدث تكرار من طراز Google لنموذج مولد الصور الخاص به – مع واقعية محسّنة ، دقة 2K ، وربما الأهم من ذلك ، تقديم النصوص التي تعمل بالفعل مع اللافتات والمنتجات والخريطة الرقمية.
بالنسبة لأي شخص عانى من خلال النص الرئاس الذي أنشأته نماذج صور الذكاء الاصطناعى السابقة ، يمثل Imagen 4 تحسنا كبيرًا.
هذه الأدوات غير موجودة في عزلة. يجمع Flow AI ، وهي ميزة اشتراك جديدة للمستخدمين المحترفين ، بين إمكانات Veo و Imagen و Gemini اللغوية في بيئة موحدة لصناعة الأفلام وتحرير المشهد. لكن هذا التكامل يأتي بسعر – 125 دولارًا شهريًا للوصول إلى مجموعة الأدوات الكاملة كجزء من فترة ترويجية حتى يتم فرض رسوم كاملة بقيمة 250 دولارًا.
الصورة: جوجل
الجوزاء: تشغيل البحث و “نشر النص”
الذكاء الاصطناعى التوليدي ليس فقط لمبدعي المحتوى. يشكل Gemini 2.5 الآن العمود الفقري لمحرك البحث المعاد تصميمه للشركة ، والذي تريد Google أن تتطور من مجمع الارتباط إلى واجهة ديناميكية ومحادثة تتعامل مع الاستعلامات المعقدة ويوفر إجابات مصنوعة ومصادر متعددة.
نظرة عامة على الذكاء الاصطناعى – حيث تحاول Google Gemini تقديم إجابات شاملة للاستعلامات دون مطالبة المستخدمين بالنقر على مواقع أخرى – الآن في أعلى صفحات البحث ، مع تقارير Google أكثر من 1.5 مليار مستخدم شهري.
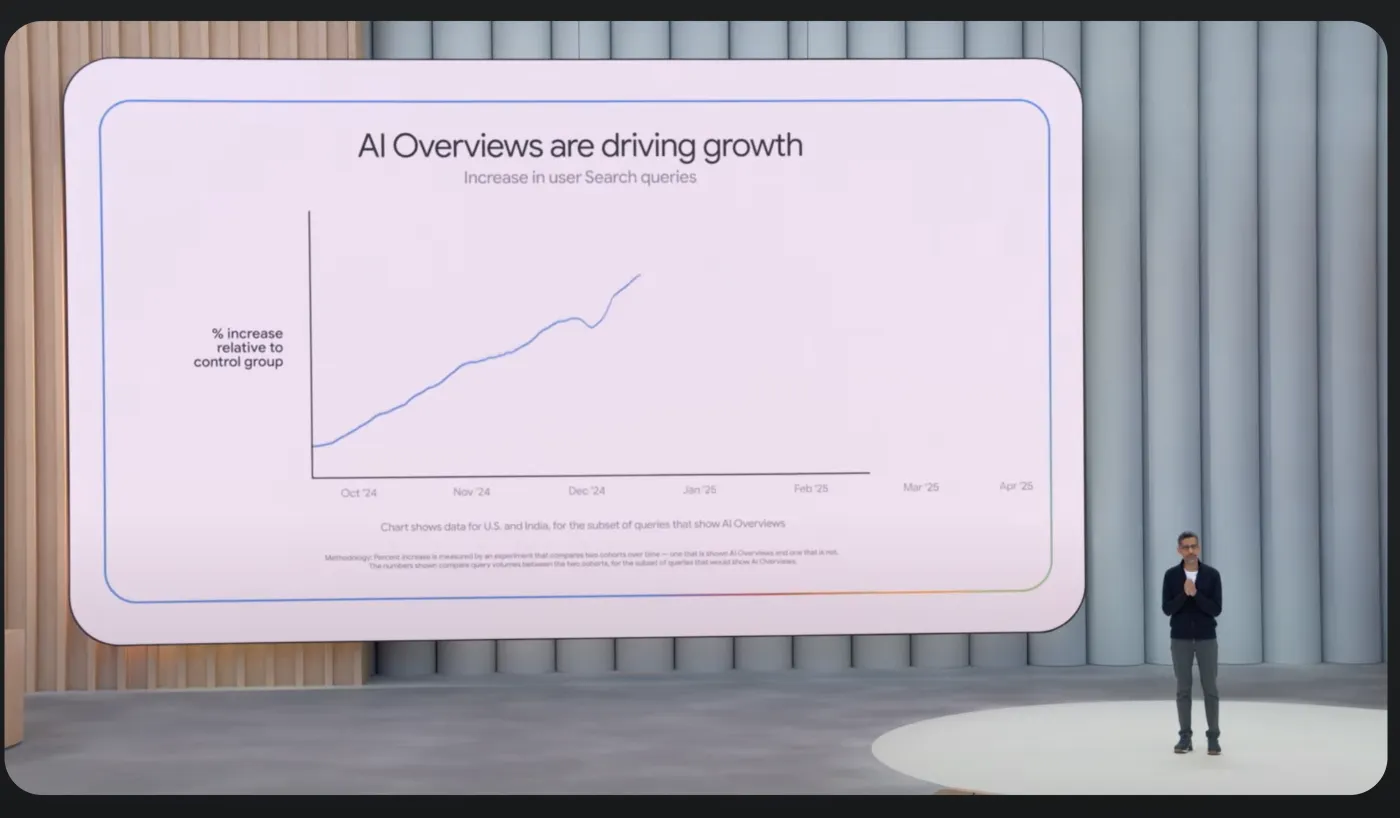
الصورة: Google عبر YouTube
هناك تطور آخر مثير للاهتمام وهو “انتشار الجوزاء” ، الذي تم بناؤه مع التكنولوجيا رائدة من قبل مختبرات Inception منذ أشهر. حتى وقت قريب ، وافق مجتمع الذكاء الاصطناعى عمومًا على أن تقنية الانحدار التلقائي تعمل بشكل أفضل لتوليد النصوص بينما تميزت تكنولوجيا الانتشار بالصور.
تقوم النماذج التلقائية بإنشاء كل رمز جديد بعد قراءة جميع الأجيال السابقة لتحديد أفضل الرمز المميز المجاور – على أساس صياغة استجابات نصية متماسكة من خلال مراجعة الإخراج المطبوخ والمسبق باستمرار.
تعمل تقنية الانتشار بشكل مختلف ، بدءًا من ملء جميع السياق بالمعلومات العشوائية والتكرير (النشر) الإخراج في كل خطوة لجعل المنتج النهائي مطابقة للمطالبة – مثالية للصور ذات اللوحات الثابتة والجمال.
قام Openai أولاً بتطبيق توليد الانحدار التلقائي على نماذج الصور ، والآن أصبحت Google أول شركة رئيسية لتطبيق توليد الانتشار على النص. هذا يعني أن النموذج يبدأ بالهراء ويقوم بتحسين الناتج بأكمله مع كل تكرار ، حيث ينتج آلاف الرموز في الثانية مع الحفاظ على الدقة – بالنسبة للسياق ، فإن Groq (وليس Xai's Grok) ، وهو أحد أسرع موفري الاستدلال في العالم ، لا يتمكن من القضاء على 275 من المركزين في الثانية ، ومقدمي الخدمات التقليدية مثل المفتوح أو القوي.
ومع ذلك ، فإن النموذج غير متاح للجمهور حتى الآن – يجب على المستخدمين المهتمين الانضمام إلى قائمة انتظار – لكن المتبنين الأوائل قد شاركوا نتائج مثيرة للإعجاب تُظهر سرعة النموذج ودقةه.
انتشار Google Gemini مجنون
إن الردود اليدوية من 2 ثانية هي إسقاط الفك
يجب أن تجربها
فيديو حقيقي: pic.twitter.com/f06cosxv2v
– Kickiniteasy (kickiniteasy) 21 مايو 2025
التدريب العملي على أدوات الذكاء الاصطناعي من Google
حصلنا على العديد من ميزات AI الجديدة من Google ، مع نتائج مختلطة اعتمادًا على المستوى.
الأبحاث العميقة قوية بشكل خاص – حتى التغلب على بديل Chatgpt. يقوم وكيل الأبحاث الشامل هذا بتقييم مئات المصادر ويقدم معلومات موثوقة مع الحد الأدنى من الأخطاء.
ما يمنحه ميزة على وكيل أبحاث Openai هو القدرة على توليد الرسوم البيانية. بعد إنتاج نص بحث كامل ، يمكن أن يكثف تلك المعلومات في شرائح جذابة بصريًا. لقد أطعمنا النموذج كل شيء عن أحدث إعلان من Google ، وقدمت معلومات دقيقة من خلال المخططات والمخططات والرسوم البيانية وخرائط العقل.
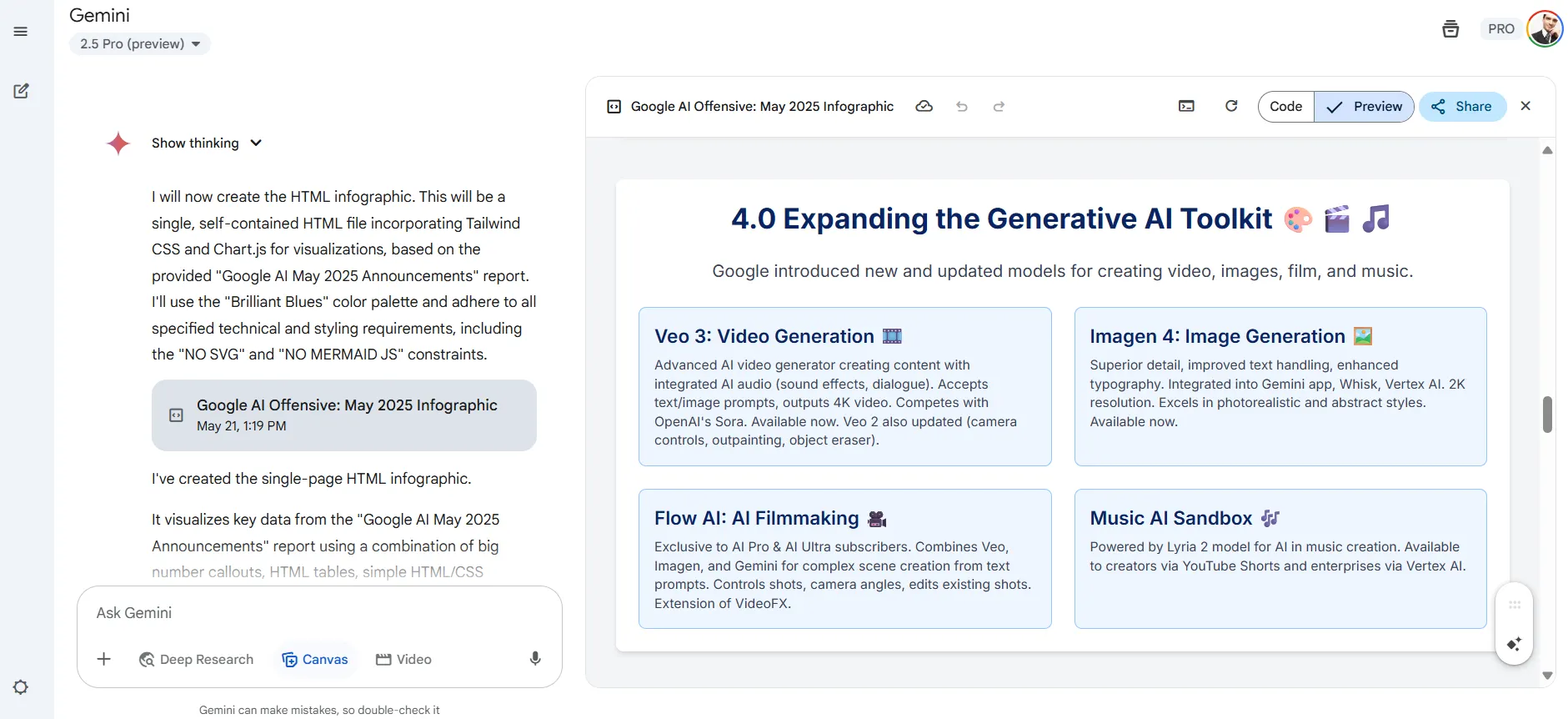
لا يزال VEO 3 حصريًا لمستخدمي Gemini Ultra ، على الرغم من أن بعض مقدمي خدمات الطرف الثالث مثل Freepik و Fal.ai يوفرون بالفعل الوصول عبر API. التدفق غير متاح للمحاولة ما لم تنفث لخطة فائقة.
يثبت Flow أنه محرر فيديو بديهي مع طرز VEO في جوهره ، مما يسمح للمستخدمين بتحرير مشاهد AI وتوسيعها وتعديلها باستخدام مطالبات نصية بسيطة.
ومع ذلك ، حتى VEO2 حصلت على القليل من الحب ، مما يجعل الحياة أسهل للمستخدمين المحترفين. الأجيال التي تحتوي على VEO2 التي يمكن الوصول إليها الآن أسرع بكثير-أنشأنا 8 ثوان من الفيديو في حوالي 30 ثانية. على الرغم من أن VEO2 يفتقر إلى الصوت ولا يدعم حاليًا سوى النص إلى Video (مع ظهور صورة إلى Video قريبًا) ، فقد فهمت مطالباتنا وحتى النص المتماسك.
تؤدي VEO2 بالفعل إلى KLING 2.0 – تعتبر ذات جودة معيارية في صناعة الفيديو التوليدي. يبدو أن الأجيال الجديدة مع VEO3 أكثر واقعية ، وتماسك ، مع صوت خلفية جيد وحوار وأصوات نابضة بالحياة.
مستحيل. فعلت ذلك. وهل هذا ، في الواقع مضحك؟
اِسْتَدْعَى:
> رجل يقوم بالوقوف الكوميدي في مكان صغير يروي نكتة (قم بتضمين النكتة في الحوار) https://t.co/gfvpassehx pic.twitter.com/lrcivap1bl– FOFR (fofrai) 20 مايو 2025
بالنسبة إلى Imagen ، من الصعب تحديد للوهلة الأولى ما إذا كانت Google تتضمن الإصدار 4 أو لا تزال تستخدم الإصدار 3 على واجهة Gemini chatbot الخاصة بها ، على الرغم من أن المستخدمين يمكنهم تأكيد ذلك من خلال الخفقان. تشير اختباراتنا الأولية إلى أن Imagen 4 تعطي الأولوية للواقعية ما لم يتم تحديدها على خلاف ذلك ، مع الالتزام الفوري والمرئيات التي تتجاوز سابقتها.
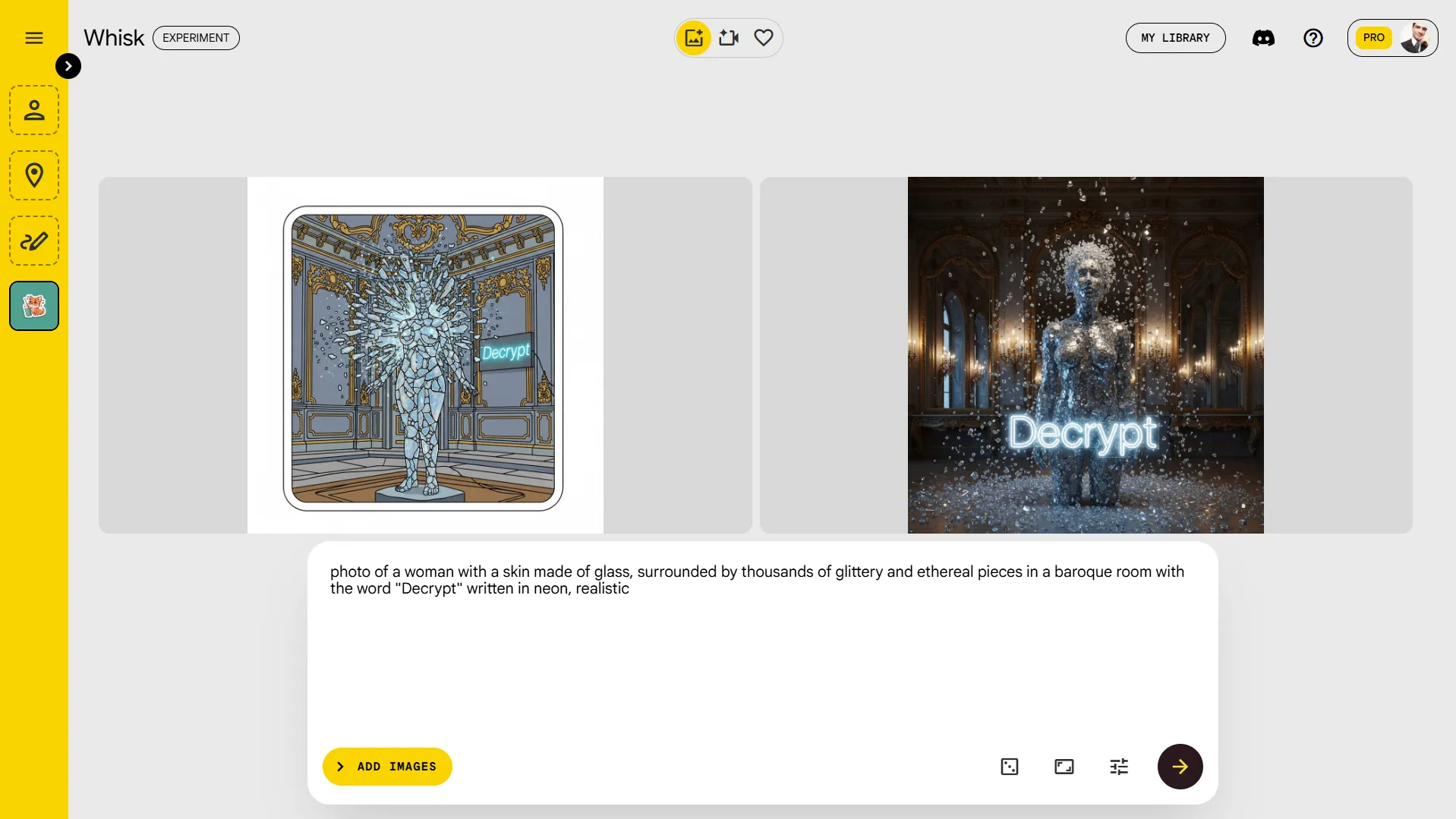
لقد أنشأنا صورة بعناصر مختلفة لا تتناسب معًا في نفس المشهد. كانت موجهنا “صورة لامرأة ذات جلد مصنوع من الزجاج ، وتحيط به الآلاف من القطع اللامعة والأثري في غرفة باروكية مع كلمة” فك التشفير “المكتوبة باللغة النيون ، واقعية”.
على الرغم من أن كل من Imagen 3 و Imagen 4 فهموا المفهوم والعناصر ، إلا أن Imagen 3 فشل في التقاط الأسلوب الواقعي – وهو ما فعله Imagen 4 بسهولة. بشكل عام ، فإن Imagen 4 مماثلة لمولدات صور SOTA ، خاصة بالنظر إلى مدى سهولة المطالبة بها.
تحسنت نظرة عامة على الصوت أيضًا ، حيث توفر النماذج الآن بسهولة أكثر من 20 دقيقة من المناقشات الكاملة على الجوزاء بدلاً من إجبار المستخدمين على التبديل إلى NotebookLM. وهذا يجعل الجوزاء واجهة أكثر اكتمالا ، مما يقلل من التجزئة التي تطلب من المستخدمين في السابق القفز بين المواقع المختلفة لمختلف الخدمات.
الجودة قابلة للمقارنة مع تلك الموجودة في دفتر NotebookLM ، مع مخرجات أطول قليلاً في المتوسط. ومع ذلك ، فإن الميزة الرئيسية ليست أن النموذج أفضل ، ولكنه مدمج الآن في واجهة المستخدم chatbot من Gemini.
Premium AI بسعر متميز
لم تخفي Google استراتيجية تسييلها. تكلف خطة “Ultra” للشركة 250 دولارًا شهريًا ، وتجمع الوصول إلى الأولوية إلى أقوى النماذج ، وأدوات التدفق الذكاء ، و 30 تيرابايت من التخزين – التي تستهدف صانعي الأفلام والمبدعين الجادين والشركات. تقوم الطبقة “AI Pro” التي تبلغ 20 دولارًا بإلغاء تأمين نموذج VEO2 السابق من Google ، إلى جانب ميزات الصور والإنتاجية لقاعدة مستخدم أوسع. أدوات توليدية أساسية – مثل إنشاء Gemini البسيط Live and Image Creation – خالية من الأدوات ، ولكن مع قيود مثل غطاء رمزي و 10 أبحاث فقط شهريًا.
يعكس هذا النهج المتدرج اتجاه سوق الذكاء الاصطناعى الأوسع: قم بالتبني الشامل مع الهدايا المجانية ، ثم قفل المحترفين بميزات مفيدة للغاية لتمريرها. رهان Google هو أن الإجراء الحقيقي (والهامش) في العمل الإبداعي المتطور وسير عمل المؤسسة الآلية-وليس مجرد مطالبات غير رسمية وتوليد ميمي.
حرره أندرو هايوارد